


Google Gemini Canvas shows real design chops
Plus a canvas-off between Google, OpenAI, and Anthropic

Finally, visual design capabilities are live in Gemini
Google caught up to the competition today by introducing canvas capabilities into its Gemini app. I wrote about canvas earlier this year when I commented on its introduction to ChatGPT by OpenAI, following on from Anthropic’s groundbreaking research and development of the artifacts concept in their Claude web interface. And Google seems to have paid attention to the widely praised artifacts functionality in Claude especially, and the first release of their efforts just went live.
But while Google may have come late to the ‘drawing’ party, its canvas offering is well worth the wait, and arguably the best of the bunch. The concept is similar to what we have already seen in the rival offerings; by activating the Canvas capability in the Gemini web interface, Gemini creates clickable interfaces through HTML, CSS and / or React code that can help visualize concepts and websites at a high level - and fast. Gemini is by far faster than Claude and ChatGPT at generating the screen / prototype / canvas / artifact (we do not yet seem to have landed on a cross-industry terminology for this capability just yet), and the end results are stellar.
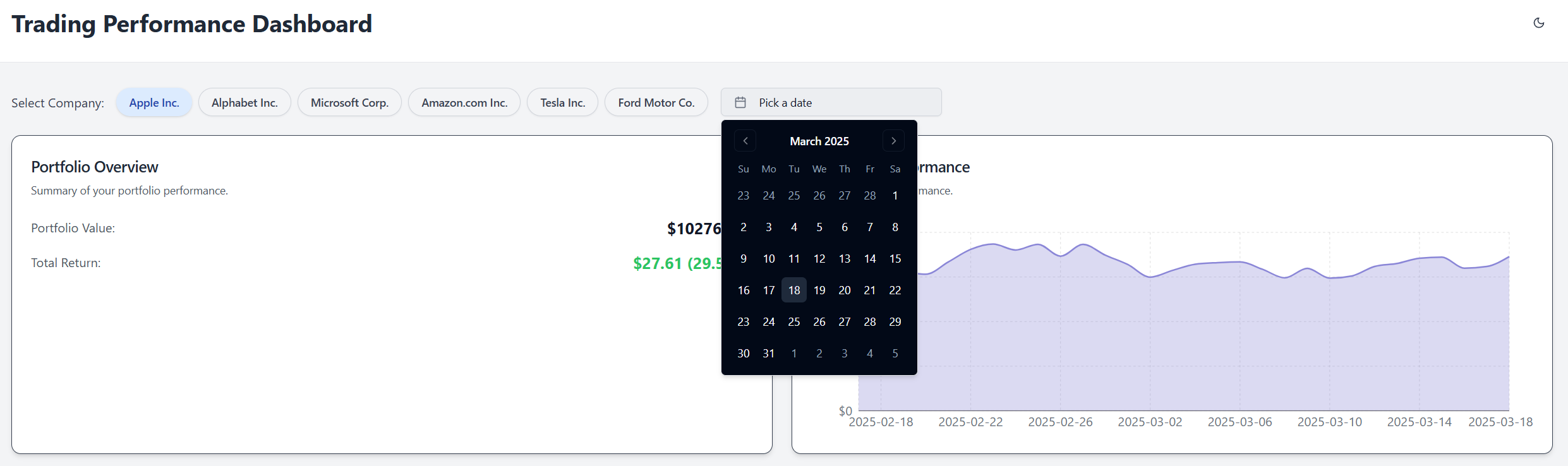
Before I write more, here is a quick visual look at what Gemini is now capable of creating. I gave it this very simple prompt: ‘Create a trading performance dashboard in React - add sample companies, history, and graphs’ and got this back on first try:

It’s a great first impression - excellent visuals, pleasing dark mode, selection pills at the top, clickable timeline graph, date selection capabilities, reasonable default companies selected etc. And I didn’t have to specify any of that - Gemini used its world knowledge to choose well-thought-out properties for the business domain I am interested in, and created an excellent first pass. And with additional instructions and model steering, designs can get much more complicated than this.
Here are our initial test findings:
Fast, really fast, generation. We said that already, but it bears repeating. The code generation just flies by and the results on the screen appear very close to instantaneously. The difference between Gemini and the other two options is noticeable.
Generated code can be edited inline by the user and the results visualized in the same way as in the original generation. Of course, visuals can also be updated by simply prompting, adding requirements or giving visual instructions that regenerate the visuals, adhering closely to the user’s instructions. And Gemini can explain selected subsets of the generated code inline - an excellent feature that keeps the user in the editing surface without the need for a separate IDE.
Generated code uses a lot of the techniques and libraries we have already seen being successfully used by Claude. Basic HTML and CSS is the default mode, but React can also be specified instead. In the latter case, the recharts Javascript library is extensively used to draw interactive charts on the screen, Tailwind is used for styling, and the lucide-react and Shadcn components are used throughout to great effect. Dark mode also seems to be the default, making for an overall better feel aesthetically.
The tool is friendly and its capabilities applicable both to technical and design audiences. And while it will not replace specialized design tools like Figma or Dreamweaver for fine-grained prototyping, its excellent visual capabilities and easy modifications through English-language instruction should help a lot in ideation and prototyping tasks.
Not everything is perfect of course. Here are a few niggles we have uncovered:
There are inconsistencies in how the code editing surface interacts with the generated visuals. We were able to put these out of sync by making minor edits to the import statements that were not reflected properly in the generated interface, for instance.
Fixing issues when manually editing the generated code is not as robust as what we have seen with ChatGPT’s canvas (although still better than the complete lack of inline editing with Claude artifacts), where the model can automatically recognize syntax issues and offers to fix them on the spot. This is definitely a miss.
The model can get stuck and stubbornly refuse to fix issues, or get into an endless loop of ineffective changes. This is an observed behavior with Gemini in other contexts as well, so it’s a pity to see it carried on in Canvas. For example, when iterating our initial prompt and asking for a dark / light mode toggle, along with a couple more changes (adding a footer, and a new company), the model got stuck in a loop implementing light mode for the Calendar. Try as we might, including switching to a new chat and giving detailed instruction, the model was just not able to solve it. Here is its best attempt - so close…
So, about that canvas-off
As part of testing, I used the same initial prompt you saw at the top with Claude Anthropic Sonnet 3.7, OpenAI GPT-4o, and GPT-4.5. You can see the results below - despite the minor Gemini niggles, I believe its results are much better.
First, here is Claude:

The model added significantly more functionality (at least double the amount of code was generated) but its visuals, especially on the line chart and pie chart sides are not impressive. And after seeing Gemini’s dark mode, this just looks too busy and underwhelming.
GPT-4o is I believe the worst of the lost - which would make sense as it is also the weakest of the four models tested. Really not much to say here, as this sad line graph just speaks for itself. Amount of code created was also about a fourth of what Gemini produced.

And finally, GPT-4.5 also disappoints, although it is slightly better than its smaller sibling. Still, with only 10% more code than 4o, the results remain quite underwhelming, even if we now have three sad lines in our chart.

Overall - we have a new canvas king
Google has done an excellent job in taking inspiration from its competitors and releasing a very polished first version of its Gemini canvas capabilities. We should expect this to pile pressure on them (especially Anthropic, which as the pioneer of these features should be furiously working to improve them now that they have seen a better implementation materialize). And while Google’s mindshare in the GenAI space is still below where I believe it deserves to be, capabilities like this one should help keep it in the conversation very favorably. I was already a big fan of their models for many reasons, including cost, size of context window, and performance among others, and this only adds to what is shaping out to be a really capable, balanced product. Both coders and designers should take a closer look and try to incorporate canvas in their workflows - it’s an excellent addition overall to a practitioner’s toolkit.
And now I will let Gemini’s canvas have the last word 😀
